

{kind=link}
https://chrome.google.com/webstore/detail/wayback-machine/fpnmgdkabkmnadcjpehmlllkndpkmiak
https://addons.mozilla.org/en-CA/firefox/addon/wayback-machine_new/
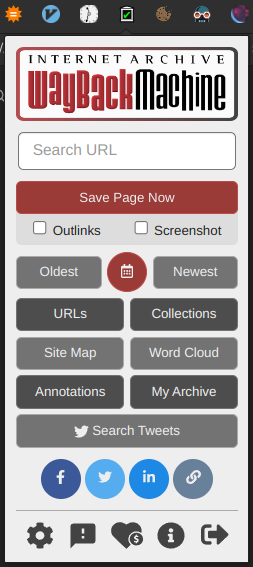
It will also detect when a webpage you are trying to visit is dead and will offer to replay an archived version
it doesn’t literally scrape the web page off your browser, it just sends a download request to the internet archive to download the webpage associated with the URL that you’re visiting
-replying from kbin because lemmy just wouldn’t let me reply… I’d been trying for over 20 minutes.
I wasn’t sure if it was using the client to capture the snapshot or not, better safe than sorry! Thanks for explaining.