

I created this account two days ago, but one of my posts ended up in the (metaphorical) hands of an AI powered search engine that has scraping capabilities. What do you guys think about this? How do you feel about your posts/content getting scraped off of the web and potentially being used by AI models and/or AI powered tools? Curious to hear your experiences and thoughts on this.
#Prompt Update

The prompt was something like, What do you know about the user [email protected] on Lemmy? What can you tell me about his interests?" Initially, it generated a lot of fabricated information, but it would still include one or two accurate details. When I ran the test again, the response was much more accurate compared to the first attempt. It seems that as my account became more established, it became easier for the crawlers to find relevant information.
It even talked about this very post on item 3 and on the second bullet point of the “Notable Posts” section.
For more information, check this comment.
Edit¹: This is Perplexity. Perplexity AI employs data scraping techniques to gather information from various online sources, which it then utilizes to feed its large language models (LLMs) for generating responses to user queries. The scraping process involves automated crawlers that index and extract content from websites, including articles, summaries, and other relevant data. It is an advanced conversational search engine that enhances the research experience by providing concise, sourced answers to user queries. It operates by leveraging AI language models, such as GPT-4, to analyze information from various sources on the web. (12/28/2024)
Edit²: One could argue that data scraping by services like Perplexity may raise privacy concerns because it collects and processes vast amounts of online information without explicit user consent, potentially including personal data, comments, or content that individuals may have posted without expecting it to be aggregated and/or analyzed by AI systems. One could also argue that this indiscriminate collection raise questions about data ownership, proper attribution, and the right to control how one’s digital footprint is used in training AI models. (12/28/2024)
Edit³: I added the second image to the post and its description. (12/29/2024).
Is it scraping or just searching?
RAG is a pretty common technique for making LLMs useful: the LLM “decides” it needs external data, and so it reaches out to configured data source. Such a data source could be just plain ol google.I think their documentation will help shed some light on this. Reading my edits will hopefully clarify that too. Either way, I always recommend reading their docs.
I guess after a bit more consideration, my previous question doesn’t really matter.
If it’s scraped and baked into the model; or if it’s scraped, indexed, and used in RAG; they’re both the same ethically.
And I generally consider AI to be fairly unethical
Well your handle is the mascot for the open LLM space…
Seriously though, why care? What we say in public is public domain.
It reminds me of people on NexusMods getting in a fuss over “how” people use the mods they publicly upload, or open source projects imploding over permissive licenses they picked… Or Ao3 having a giant fuss over this very issue, and locking down what’s supposed to be a public archive.
I can hate entities like OpenAI all I want, but anything I put out there is fair game.
Oh, no. I don’t dislike it, but I also don’t have strong feelings about it. I’m just interested in hearing other people’s opinions; I believe that if something is public, then it is indeed public.
the fediverse is largely public. so i would only put here public info. ergo, i dont give a shit what the public does with it.
But what if a shitposting AI posts all the best takes before we can get to them.
Is the world ready for High Frequency Shitposting?
Is the world ready for High Frequency Shitposting?
The lemmy world? Not at all. Instances have no automated security mechanisms. The mod system consisting mostly of self important ***'s would break down like straw. Users cannot hold back, but would write complaints in exponential numbers, or give up using lemmy within days…
I don’t think it’s unreasonable to be uneasy with how technology is shifting the meaning of what public is. It used to be walking the dog meant my neighbors could see me on the sidewalk while I was walking. Now there are ring cameras, etc. recording my every movement and we’ve seen that abused in lots of different ways.
People think there are only two categories, private and public, but there are now actually three: private, public, and panopticon.
The internet has always been a grand stage, though. We’re like 40 years into this reality at this point.
I think people who came-of-age during Facebook missed that memo, though. It was standard, even explicitly recommended to never use your real name or post identifying information on the internet. Facebook kinda beat that out of people under the guise of “only people you know can access your content, so it’s ok”. People were trained into complacency, but that doesn’t mean the nature of the beast had ever changed.
People maybe deluded themselves that posting on the internet was closer to walking their dog in their neighbourhood than it was to broadcasting live in front of international film crews, but they were (and always have been) dead wrong.
Our choices regarding security and privacy are always compromises. The uneasy reality is that new tools can change the level of risk attached to our past choices. People may have been OK with others seeing their photos but aren’t comfortable now that AI deep fakes are possible. But with more and more of our lives being conducted in this space, do even knowledgable people feel forced to engage regardless?
We’re like 40 years into this reality at this point.
We are not 40 years into everyone’s every action (online and, increasingly, even offline via location tracking and facial recognition cameras) being tracked, stored in a database, and analyzed by AI. That’s both brand new and way worse than even what the pre-Facebook “don’t use your real name online” crowd was ever warning about.
I mean, yes, back in the day it was understood that the stuff you actively write and post on Usenet or web forums might exist forever (the latter, assuming the site doesn’t get deleted or at least gets archived first), but (a) that’s still only stuff you actively chose to share, and (b) at least at the time, it was mostly assumed to be a person actively searching who would access it – that retrieving it would take a modicum of effort. And even that was correctly considered to be a great privacy risk, requiring vigilance to mitigate.
These days, having an entire industry dedicated to actively stalking every user for every passive signal and scrap of metadata they can possibly glean, while moreover the users themselves are much more “normie”/uneducated about the threat, is materially even worse by a wide margin.
I couldn’t agree more!
I’m okay with it as long as it’s not locked to the exclusive use of one entity.
It seems quite inevitable that AI web crawlers will catch all of us eventually, although that said, I don’t think perplexity knows that I’ve never interacted with szmer.info, nor said YES as a single comment.
theyre not training it
its basically just a glorified search engine.Not Perplexity specifically; I’m taking about the broader “issue” of data-mining and it’s implications :)
Could lemmy add random text only readable by bot on every post… or should I add it somehow myself every time I type something?
spoiler
growing concern over the outbreak of a novel coronavirus in Wuhan, China. This event marked the beginning of what would soon become a global pandemic, fundamentally altering the course of 2020 and beyond.
As reports began to surface about a cluster of pneumonia cases in Wuhan, health officials and scientists scrambled to understand the nature of the virus. The World Health Organization (WHO) was alerted, and investigations were launched to identify the source and transmission methods of the virus. Initial findings suggested that the virus was linked to a seafood market in Wuhan, raising alarms about zoonotic diseases—those that jump from animals to humans.
The situation garnered significant media attention, as experts warned of the potential for widespread transmission. Social media platforms buzzed with discussions about the virus, its symptoms, and preventive measures. Public health officials emphasized the importance of hygiene practices, such as handwashing and wearing masks, to mitigate the risk of infection.
As the world prepared to ring in the new year, the implications of this outbreak were still unfolding. Little did anyone know that this would be the precursor to a global health crisis that would dominate headlines, reshape societies, and challenge healthcare systems worldwide throughout 2020 and beyond. The events of late December 2019 set the stage for a year of unprecedented change, highlighting the interconnectedness of global health and the importance of preparedness in the face of emerging infectious diseases.
Interesting question… I think it would be possible, yes. Poison the data, in a way.
As with any public forum, by putting content on Lemmy you make it available to the world at large to do basically whatever they want with. I don’t like AI scrapers in general, but I can’t reasonably take issue with this.
There are at least one or two Lemmy users who add a CC or non-AI license footer to their posts. Not that it’s do anything, but it might be fun to try and get the LLM to admit it’s illegally using your content.
Those… don’t hold any weight lol. Once you post on any website, you hand copyright over to the website owner. That’s what gives them permission to relay your message to anyone reading the website. Copyright doesn’t do anything to restrict readers of the content (I.e. model trainers). Only publishers.
Don’t give me any ideas now >:)
Sadly it hasn’t been proven in court yet that copyright even matters for training AI.
And we damn well know it doesn’t for Chinese AI models.
It’d be hilarious if the model spat out the non-AI license footer in response to a prompt.
I did tell one of them a few months ago that all they’re going to do is train the AI that sometimes people end their posts with useless copyright notices. It doesn’t understand anything. But superstitious monkeys gonna be superstitious monkeys.
Whatever I put on Lemmy or elsewhere on the fediverse implicitly grants a revocable license to everyone that allows them to view and replicate the verbatim content, by way of how the fediverse works. You may apply all the rights that e.g. fair use grants you of course but it does not grant you the right to perform derivative works; my content must be unaltered.
When I delete some piece of content, that license is effectively revoked and nobody is allowed to perform the verbatim content any longer. Continuing to do so is a clear copyright violation IMHO but it can be ethically fine in some specific cases (e.g. archival).
Due to the nature of how the fediverse, you can’t expect it to take effect immediately but it should at some point take effect and I should be able to manually cause it to immediately come into effect by e.g. contacting an instance admin to ask for a removed post of mine to be removed on their instance aswell.
I think it’s great, because there’s plenty of opportunity to covfefe
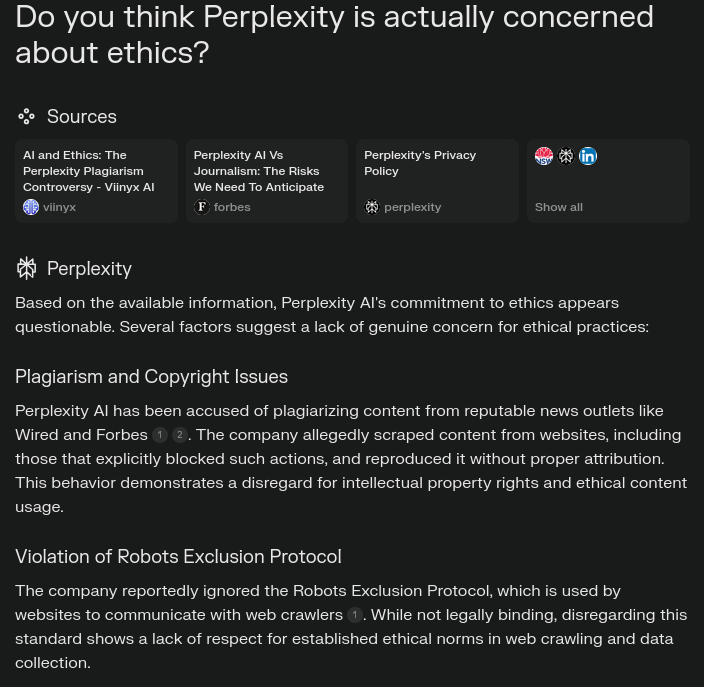
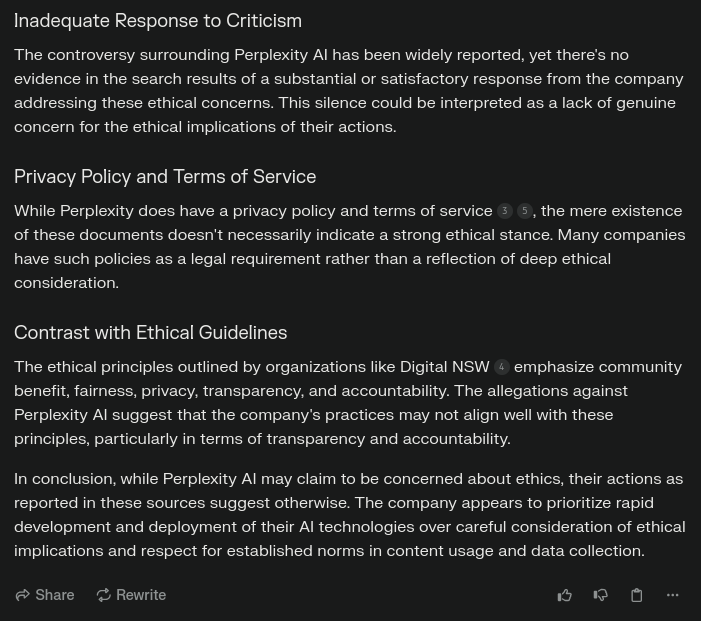
I think this is inevitable, which is why we (worldwide) need laws where if a model scrapes public data should become open itself as well.
I run my own instance and have a long list of user agents I flat out block, and that includes all known AI scraper bots.
That only prevents them from scraping from my instance, though, and they can easily scrape my content from any other instance I’ve interacted with.
Basically I just accept it as one of the many, many things that sucks about the internet in 2024, yell “Serenity Now!” at the sky, and carry on with my day.
I do wish, though, that other instances would block these LLM scraping bots but I’m not going to avoid any that don’t.
you might be interested to know that UA blocking is not enough: https://feddit.bg/post/13575
the main thing is in the comments
No matter how I feel about it, it’s one of those things I know I will never be able to do a fucking thing about, so all I can do is accept it as the new reality I live in.
I’ve been thinking for a while about how a text-oriented website would work if all the text in the database was rendered as SVG figures.
Not very friendly to the disabled?
Aside from that. Accessibility standards are hardly considered even now and I’d rather install a generated audio version option with some audio poisoning to mess with the AIs listening to it.








{kind=link}